iOSer都知道LLVM(Low Level Virtual Machine)是Xcode自带的编译器,而在LLVM诞生之前,Apple一直依赖另一个开源编译器GCC。随着Apple收购乔布斯的创业公司NextStep,面向对象语言Objective-C正式成为Apple官方的开发语言。由于当时GCC社区开发者未能及时支持OC的新语言特性,加上GCC开发者与Apple在编译器支持模块化调用方面存在分歧,最终让Apple选择分道扬镳,并转头拥抱了另一个开源项目LLVM。
这场”分手”的深层原因其实更加复杂:GCC的GPL许可证要求任何基于GCC的修改都必须开源,这对于Apple这样重视知识产权的公司来说是难以接受的。而且GCC的代码库经过20多年的发展,已经变成了一个高度耦合、难以扩展的庞然大物。Apple需要的是一个能够快速迭代、支持新语言特性、并且可以深度集成到IDE中的现代化编译器。
LLVM起源于2000年,是由美国UIUC大学的Chris Lattner博士发起,Chris Lattner也是后来的Swift之父。最初LLVM是Chris Lattner的硕士论文项目,旨在构建一个”终身代码优化系统”(Lifelong Program Analysis & Transformation),可以在编译时、链接时、运行时甚至闲置时对代码进行持续优化。这个大胆的想法吸引了Apple的注意。
在Apple的资助下,LLVM得到了飞速的发展。2005年,Apple雇用了Chris Lattner,并组建了专门的LLVM开发团队。同时始于2007开发的Clang,因编译速度快、占内存少、错误诊断信息友好、代码质量高,最终替代笨重的GCC成为LLVM的新前端。Clang的编译速度比GCC快3倍,内存占用减少5倍,这对于大型项目的编译体验提升是巨大的。更重要的是,Clang从设计之初就考虑了IDE集成,提供了丰富的API供开发工具调用,这为Xcode的代码补全、实时错误检测、重构等功能提供了基础。
LLVM和Clang不断完善功能的同时,也在Apple的MacOS和Xcode IDE中得到工业级的应用和推广。2013年,Apple正式宣布废弃GCC,LLVM/Clang成为Xcode的默认编译器。在与Apple的相互成就中,LLVM一跃成为了最领先的开源编译器之一,目前已被Google(用于Android NDK)、Intel、AMD、NVIDIA等科技巨头广泛采用。
LLVM设计理念
与GCC不同,LLVM设计之初就注重模块化和可扩展性,这是一种设计哲学的根本性差异。比如LLVM的优化器,它支持开发者选择Pass的类型和执行顺序,提供基于模块或库的可组装能力。每个Pass都是一个独立的转换单元,可以单独测试、单独优化、单独替换。相对之下,GCC的优化器则是由大量高度耦合的代码组成,很难进行拆分和选择性使用。GCC的优化passes之间存在隐式依赖,修改一个pass可能影响其他多个pass的行为。
模块化的设计理念还体现在LLVM的三段式架构设计中:LLVM通过Libraries collection完美实现了传统编译器想要的编译前端、编译优化器和编译后端三个核心部件,并且通过中间表示(IR)作为各个部件之间的接口。这种设计带来了几个关键优势:
编译前端(Frontend):负责将各种高级语言源代码转换为LLVM中间表示(IR)。不同的语言可以有不同的前端实现,比如Clang处理C/C++/Objective-C,Swift前端处理Swift语言,Rust前端处理Rust语言。前端的主要任务包括词法分析、语法分析、语义分析、类型检查,最终生成抽象语法树(AST)并将其降低(Lower)为LLVM IR。
编译优化器(Optimizer):对中间表示进行各种优化,以提高代码性能。LLVM的优化器采用Pass-based架构,每个Pass负责一种特定的优化。优化可以分为多个层次:函数内优化(Intra-procedural)、过程间优化(Inter-procedural)、全局优化(Whole Program)。LLVM提供了超过100个内置Pass,并且支持用户自定义Pass。
编译后端(Backend):将优化后的中间表示转换为目标机器的代码。后端需要完成指令选择(Instruction Selection)、寄存器分配(Register Allocation)、指令调度(Instruction Scheduling)等任务。LLVM通过TableGen工具和目标描述文件(.td)来描述不同架构的特性,使得添加新的目标平台变得相对容易。
通过三段式的架构设计,LLVM可以通过灵活切换不同编程语言的前端实现,转化成通用的中间表示,并通过编译后端进行本机编译或者交叉编译适配成目标机器代码,从而实现了高可扩展性。LLVM能够快速支持各种新的编程语言,主要得益于三段式架构的高可扩展性。
这种架构的数学模型可以表示为:如果有M种源语言和N种目标架构,传统编译器需要M×N个编译器实现,而LLVM只需要M个前端+N个后端。这种O(M+N)的复杂度远低于O(M×N),大大降低了开发和维护成本。
更重要的是,LLVM IR作为中间层,提供了一个稳定的契约接口。前端开发者不需要了解后端的实现细节,后端开发者也不需要了解各种语言的语法特性。这种解耦使得编译器的各个部分可以并行开发和演进。
LLVM架构
传统编译器的三段式架构:

编译前端(Frontend)通过词法、语法、语义一系列分析,构建抽象语法树(AST),AST可以转换成某种中间表示(IR),作为编译优化器(Optimizer)的输入。编译优化器负责对中间代码进行优化,比如无用代码消除(Dead Code Elimination)、冗余指令合并(Common Subexpression Elimination)、函数内联(Function Inlining)等,以提升代码运行时性能。编译优化器输入IR,最终输出是优化过的IR。经过编译优化器(Optimizer)优化后的IR经过编译后端(Backend)转换成目标平台的机器码。
这个过程中,词法分析(Lexical Analysis)将源代码转换为token流,语法分析(Syntax Analysis)根据语言的文法规则构建语法树,语义分析(Semantic Analysis)进行类型检查、作用域解析等工作。这些步骤在编译原理中被称为编译器的”前端工作”。
通过这种组件化的设计,任何编程语言的编译器只要实现了上述3个部件,就能够把对应语言编写的源代码编译成目标平台可运行的机器代码。
于是支持多语言多平台的新架构被提出:
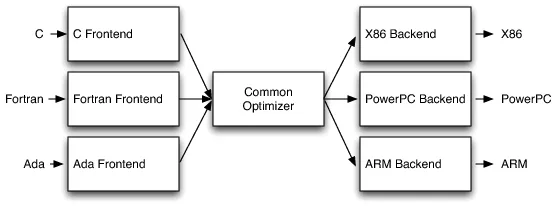
上述新架构支持不同的编程语言生成统一的中间表示(IR),新语言只用实现一个新的编译前端(Frontend),编译优化器(Optimizer)和编译后端(Backend)则可以复用。这种架构的核心思想是”一次编写,多次复用”(Write Once, Reuse Many Times)。
在现存的编译器中,JVM、.Net虚拟机提供了定义良好的中间表示字节码,理论上任意语言只要实现编译前端,支持把源代码转成字节码就可以使用JVM或者.Net虚拟机。但是运行时强制JIT编译、GC等机制并不适合像C这样的系统级编程语言。JVM和.Net的设计目标是托管环境(Managed Environment),它们假设有一个运行时系统来管理内存、处理异常、提供安全检查。这对于C/C++这种需要手动管理内存、直接操作硬件的语言来说是不合适的。
而另一个新架构的代表GCC,则因为早期设计中存在的耦合问题比如编译后端(Backend)需要遍历编译前端(Frontend)的AST生成调试信息,编译前端(Frontend)生成编译后端(Backend)的数据结构,以及全局变量和数据结构的滥用,导致三大编译组件耦合,代码复用性较差。GCC的这些设计缺陷是历史包袱,很难通过重构来解决,因为数百万行的代码已经基于这些假设编写。
LLVM在实现三段式架构中,汲取了GCC的教训,在设计中采用了严格的模块化设计,整个编译器由一系列可复用的库组成。这些库包括:
- libLLVMCore:核心IR和基础数据结构
- libLLVMAnalysis:各种分析pass(控制流分析、数据流分析、别名分析等)
- libLLVMTransform:各种优化pass(常量折叠、循环优化、内联等)
- libLLVMCodeGen:代码生成框架
- libLLVMTarget:目标机器描述
- libLLVMSupport:通用工具和基础设施
每个库都有清晰的接口定义和职责划分,库之间的依赖关系是单向的、非循环的。这种设计使得开发者可以只链接需要的库,减少最终可执行文件的大小。例如,如果你只需要分析LLVM IR而不需要生成机器码,就可以只链接分析相关的库。
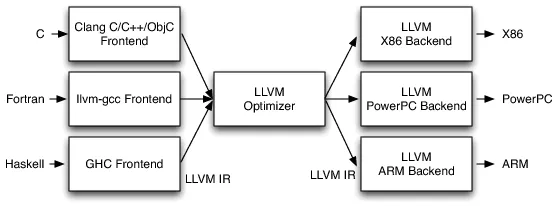
LLVM的架构体现了软件工程中的几个重要原则:
- 关注点分离(Separation of Concerns):每个组件只关注自己的职责
- 接口与实现分离:通过IR作为稳定的接口,隔离前端和后端
- 开放封闭原则:对扩展开放(可以添加新的Pass、新的前端、新的后端),对修改封闭(不需要修改核心代码)
LLVM IR
LLVM IR(Intermediate Representation)是LLVM整个架构的核心,它是一种强类型的、SSA(Static Single Assignment)形式的低级虚拟指令集。LLVM IR有三种等价的表示形式:
- 内存形式:在编译器内部使用的C++对象
- 汇编形式:以.ll结尾的文本文件,人类可读
- 二进制形式:以.bc结尾的bitcode文件,紧凑高效
LLVM IR是.ll结尾的文件示例:
1 | define i32 @add1(i32 %a, i32 %b) { |
让我们深入分析一下这段IR:
类型系统:i32表示32位整数,LLVM IR支持任意位宽的整数(i1到i2^23-1),还支持浮点数、指针、数组、结构体等复杂类型。这种强类型系统使得很多错误可以在编译时被发现。
SSA形式:每个虚拟寄存器(如%tmp1、%tmp2)只被赋值一次。SSA形式极大地简化了数据流分析和优化。例如,在SSA形式下,变量的use-def链(使用-定义链)是明确的,不需要额外的分析就能知道一个值来自哪里。
基本块结构:函数被划分为多个基本块(Basic Block),每个基本块是一个顺序执行的指令序列,没有内部跳转。基本块是LLVM进行控制流分析和优化的基本单位。
控制流指令:br指令实现条件跳转,ret指令返回函数。LLVM IR还支持switch、invoke(用于异常处理)等控制流指令。
对应的C语言代码如下:
1 | unsigned add1(unsigned a, unsigned b) { |
注意add2是一个尾递归函数,LLVM的尾调用优化(Tail Call Optimization)pass可以将其转换为循环,消除递归调用的开销。这就是Pass架构的威力:通过组合不同的Pass,可以实现复杂的优化策略。
LLVM IR的设计目标包括:
- 语言中立性:不偏向任何特定的源语言或目标架构
- 可扩展性:容易添加新的指令和类型
- 可分析性:方便进行数据流分析、控制流分析
- 可优化性:便于实现各种优化算法
- 可调试性:保留源代码的调试信息
LLVM IR还支持元数据(Metadata),可以附加额外的信息而不影响程序的语义。例如,调试信息、类型信息、优化提示等都可以通过元数据来表达。这使得LLVM IR在保持简洁性的同时,又能承载丰富的语义信息。
LLVM Optimizer
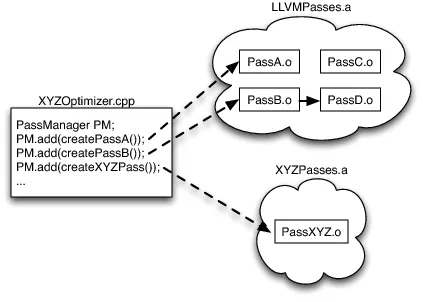
LLVM优化器提供一系列Pass进行代码优化,这些Pass一般由C++编写,被编译成.o文件集成在.a库中。Pass架构是LLVM最核心的设计之一,它提供了一个统一的框架来实现各种分析和优化。
Pass的分类:
- ModulePass:在整个模块(通常是一个编译单元)上操作,可以访问模块中的所有函数和全局变量。适合全局优化,如跨过程优化(Inter-Procedural Optimization, IPO)。
- FunctionPass:在单个函数上操作,是最常见的Pass类型。大多数优化都是FunctionPass。
- LoopPass:在循环上操作,专门用于循环优化。
- RegionPass:在代码区域上操作,介于BasicBlockPass和FunctionPass之间。
- BasicBlockPass:在单个基本块上操作,最细粒度的Pass。
Pass可以通过PassManager进行创建和添加,方便开发者自由选择Pass进行组合和编排,同时LLVM也支持自定义Pass。PassManager负责:
- 按依赖关系排序Pass的执行顺序
- 管理Pass之间的数据传递
- 缓存分析结果,避免重复计算
- 并行执行独立的Pass(在新版LLVM中)
以冗余指令合并Pass(InstructionCombine.cpp源码实现)为例:
1 |
|
实际的InstructionCombining pass非常复杂,包含了数百种优化模式。它使用模式匹配技术,将常见的低效代码模式转换为更高效的形式。例如:
- 代数简化:
x + 0 => x,x * 1 => x,x - x => 0 - 强度削弱:
x * 2 => x << 1,x / 8 => x >> 3 - 常量折叠:
3 + 5 => 8 - 公共子表达式消除:避免重复计算
常见的Pass列表及其详细说明:
InstructionCombining:合并简单的指令,以生成更高效的代码。这是运行最频繁的pass之一,会被执行多次。它使用启发式规则来识别和转换代码模式。
**GVN (Global Value Numbering)**:全局值编号,用于消除冗余的计算。通过给每个表达式分配一个编号,如果两个表达式的编号相同,说明它们计算的是同一个值,可以消除其中一个。GVN不仅能消除完全相同的表达式,还能处理等价但形式不同的表达式。
Reassociate:重新关联算术表达式,以优化代码布局。例如,将
(a + b) + c转换为a + (b + c),为后续的优化创造机会。这个pass经常与ConstantPropagation配合使用,将常量”吸”到表达式的一侧。**SCCP (Sparse Conditional Constant Propagation)**:稀疏条件常量传播,用于优化条件分支。SCCP是一个强大的过程间优化,它同时进行常量传播和死代码消除。”稀疏”是指它只分析可达的代码,跳过死代码。
SimplifyCFG:简化控制流图,减少不必要的分支和跳转。例如,消除空的基本块、合并只有一个前驱的基本块、消除恒为真或假的条件跳转。SimplifyCFG是最有效的优化pass之一,能显著减少代码大小。
LoopUnroll:循环展开,通过减少循环迭代次数和分支开销来提高执行速度。循环展开需要在代码大小和执行速度之间权衡。LLVM使用启发式算法来决定展开因子,考虑循环体大小、迭代次数、目标架构的指令缓存大小等因素。
LoopIdiomRecognize:识别并优化常见的循环模式。例如,识别出循环是在做内存拷贝(memcpy)或内存设置(memset),然后用高度优化的库函数替换整个循环。这个pass体现了”模式识别”的思想。
MemCpyOptimizer:优化内存复制操作。可以消除冗余的memcpy、将多个小的memcpy合并为一个大的、将memcpy转换为一系列load/store指令(如果更高效的话)。
TailCallElim:消除尾调用,优化函数调用开销。将尾递归转换为循环,避免栈溢出。这对函数式编程风格的代码特别重要。
ConstantPropagation:常量传播,将常量值直接替换到使用它的地方。这是最基础但也最重要的优化之一,它为许多其他优化创造了条件。
DeadStoreElimination:消除死存储,即那些从未被读取的存储操作。例如,如果一个变量被赋值后立即被重新赋值,第一次赋值就是死存储。
**ADCE (Aggressive Dead Code Elimination)**:激进的死代码消除,删除无法到达的代码和没有副作用的无用计算。ADCE比简单的死代码消除更激进,它会追踪数据流,找出所有不影响程序输出的计算。
PromoteMemoryToRegister:将内存访问提升为寄存器访问,减少内存访问开销。这个pass将局部变量从栈内存提升到虚拟寄存器,是性能优化的关键。它也是构造SSA形式的重要步骤。
SimplifyLibCalls:简化库函数调用,将其替换为更高效的代码。例如,
strlen(s)可以在编译时计算如果s是常量字符串;printf("%s", s)可以替换为puts(s)。JumpThreading:线程化跳转,通过预测跳转目标来优化控制流。如果一个跳转的目标很明显,可以直接跳到最终目标,跳过中间的跳转。这减少了分支预测失败的代价。
CorrelatedValuePropagation:相关值传播,利用值之间的关系来优化代码。例如,如果
x < 10为真,那么在这个条件的作用域内,x的值就被约束了,可以进行更激进的优化。IndVarSimplify:归纳变量简化,优化循环中的归纳变量。归纳变量是在循环中按规律变化的变量(如循环计数器)。这个pass可以消除冗余的归纳变量,简化归纳变量的更新表达式。
**LICM (Loop-Invariant Code Motion)**:循环不变代码外提,将循环内不变的计算移到循环外。这是循环优化的基础技术,可以显著减少重复计算。
BlockPlacement:块放置,优化基本块在函数中的布局。通过将经常连续执行的基本块放在一起,可以提高指令缓存的命中率,减少分支预测失败。
InlineFunction:内联函数,将小函数的代码直接插入到调用它的地方。函数内联消除了调用开销,更重要的是它为其他优化创造了机会。但过度内联会导致代码膨胀,需要权衡。
Pass的执行顺序非常重要。LLVM提供了几个预定义的Pass Pipeline:
- -O0:不进行优化,只做必要的代码生成
- -O1:基础优化,平衡编译速度和代码质量
- -O2:标准优化,大多数生产代码使用这个级别
- -O3:激进优化,包括内联、向量化等,可能增加代码大小
- -Os:优化代码大小
- -Oz:更激进的代码大小优化
每个优化级别对应一个Pass序列,例如-O2会运行60多个Pass。Pass的顺序是精心设计的,因为有些Pass会为其他Pass创造优化机会。例如,InstructionCombining和SimplifyCFG经常交替执行,因为它们会相互创造优化机会。
LLVM代码生成
X86平台代码生成过程:

代码生成(Code Generation)是编译器后端的核心任务,它将平台无关的LLVM IR转换为特定目标平台的机器码。这个过程分为几个阶段:
1. 指令选择(Instruction Selection)
将LLVM IR指令映射到目标架构的机器指令。这不是简单的一对一映射,因为:
- 一条IR指令可能对应多条机器指令
- 多条IR指令可能可以组合成一条机器指令(指令融合)
- 需要考虑目标架构的指令集特性(如SIMD指令)
LLVM使用两种指令选择策略:
- SelectionDAG:将IR转换为有向无环图(DAG),然后在DAG上进行模式匹配和代码生成。这是默认的方法,支持复杂的优化。
- FastISel:快速指令选择,用于快速编译(如JIT场景),牺牲代码质量换取编译速度。
2. 指令调度(Instruction Scheduling)
确定指令的执行顺序,以最大化流水线效率、减少数据冒险。现代CPU有多个执行单元,可以并行执行多条指令,指令调度的目标是充分利用这种并行性。
3. 寄存器分配(Register Allocation)
这是代码生成中最复杂的问题之一。LLVM IR使用无限个虚拟寄存器,但真实的CPU只有有限个物理寄存器。寄存器分配器需要将虚拟寄存器映射到物理寄存器,并在寄存器不够用时将值”溢出”到栈内存。
LLVM提供多种寄存器分配算法:
- Fast:快速但生成的代码质量较低
- Basic:基础算法,质量中等
- Greedy:贪心算法,这是默认的,生成高质量代码
- PBQP:基于分区的二次规划,理论上最优但很慢
寄存器分配是NP完全问题,LLVM使用启发式算法来近似求解。
4. Prologue/Epilogue插入
在函数入口和出口插入代码,处理栈帧的建立和销毁、保存和恢复callee-saved寄存器等。
5. 汇编指令发射
生成最终的汇编代码或机器码。
LLVM提供DSL语言(TableGen)对目标平台进行一组.td文件的特性描述,最终通过tblgen工具进行处理,生成特定平台的代码。TableGen是一种声明性语言,用于描述:
- 寄存器类和寄存器
- 指令格式和编码
- 调用约定
- 指令的模式匹配规则
例如,X86目标的描述文件包含几万行代码,详细描述了X86架构的方方面面。通过这种方式,添加新的目标架构主要是编写目标描述文件,而不需要修改代码生成框架本身。
LLVM还提供链接时优化(Link-Time Optimization, LTO)和安装时优化:

链接时优化
链接时优化(LTO):在链接阶段进行全程序优化。传统的编译是以编译单元(通常是一个.c文件)为单位的,编译器无法看到跨编译单元的优化机会。LTO通过在链接时将所有编译单元的LLVM IR重新读入,进行全程序分析和优化。这可以实现:
- 跨模块的函数内联
- 跨模块的常量传播
- 死代码消除(删除未使用的全局函数和变量)
- 虚函数去虚化
LTO有两种模式:
- Full LTO:将所有IR合并后优化,效果最好但编译慢
- ThinLTO:轻量级LTO,平衡编译速度和优化效果,可以并行化

安装时优化
安装时优化(Install-Time Optimization):在程序安装到最终设备时,根据目标设备的具体硬件特性进行优化。例如,可以针对特定的CPU型号选择最佳的指令集扩展(如AVX2、AVX-512)。这种优化在移动设备上特别有用,因为不同设备的硬件差异很大。
这种”延迟优化”的思想是LLVM”终身优化”理念的体现:优化不仅发生在编译时,还可以发生在链接时、安装时,甚至运行时(通过JIT)。
LLVM工具链
Talk is cheap, show me the code.
下面通过简单的C语言代码示例,来看看C源码是怎么被LLVM编译器一步步处理的。这个过程展示了从高级语言到机器码的完整转换流程。
C实现一个简单的加法:
1 | int add() { |
步骤1:生成LLVM IR
通过clang把C源码转换成LLVM IR:
1 | clang -emit-llvm -S Test.c -o Test.ll |
参数说明:
-emit-llvm:生成LLVM IR而不是汇编-S:生成文本格式(.ll),如果是-c则生成bitcode(.bc)-O0到-O3:可以指定优化级别(默认是-O0)
通过cat Test.ll打印.ll文件内容:
1 | ; ModuleID = 'Test.c' |
关键观察:
- 因为使用了
-O0(默认),代码没有优化,包含大量冗余的load/store - 每个局部变量都分配了栈空间(alloca)
- SSA形式:每个值只赋值一次
- 包含元数据:
target datalayout描述数据布局,target triple描述目标平台 attributes描述函数属性:noinline(不内联)、optnone(不优化)等
步骤2:优化LLVM IR
使用冗余指令合并Pass优化IR:
1 | opt -instcombine -S Test.ll -o Output.ll |
也可以使用标准优化级别:
1 | opt -O2 -S Test.ll -o Output.ll # 使用-O2级别的所有优化 |
优化后的IR会更简洁:
1 | define i32 @add() { |
这就是常量折叠(Constant Folding)和常量传播(Constant Propagation)的威力。编译器发现a、b、c都是常量,直接在编译时计算出结果。
步骤3:生成Bitcode
将LLVM IR转换成bitcode(二进制格式,更紧凑):
1 | llvm-as Test.ll -o Test.bc |
bitcode文件是LLVM IR的二进制表示,具有以下优势:
- 文件更小(通常是.ll文件的1/3)
- 加载更快
- 适合用于链接时优化(LTO)
- 可以跨平台分发(比如iOS的bitcode)
可以用llvm-dis将bitcode转回文本格式:
1 | llvm-dis Test.bc -o Test.ll |
步骤4:生成汇编代码
将bitcode转换成目标平台汇编:
1 | llc Test.bc -o Test.s |
可以指定目标架构:
1 | llc -march=x86-64 Test.bc -o Test_x86.s # 生成x86-64汇编 |
这展示了LLVM的跨平台能力:从同一个IR可以生成不同架构的代码。
打印汇编文件内容(ARM64平台):
1 | .section __TEXT,__text,regular,pure_instructions |
汇编代码分析:
.section、.globl等是汇编指示符sub sp, sp, #16:分配栈空间,ARM64要求16字节对齐w8、w9、w0是32位寄存器(对应LLVM IR的i32)str/ldr是存储/加载指令.cfi_*指令用于生成调用帧信息(Call Frame Information),用于异常处理和调试
如果使用优化过的IR生成汇编,会简洁得多:
1 | _add: |
步骤5:使用JIT执行
使用即时编译器(JIT)直接执行bitcode:
1 | lli Test.bc |
lli是LLVM的解释器/JIT执行器,它可以:
- 解释执行LLVM IR(慢但不需要生成机器码)
- JIT编译为机器码后执行(快)
LLVM的JIT引擎(MCJIT和新的ORC JIT)被广泛用于:
- 动态语言(如Julia)的JIT编译
- 数据库查询优化
- 着色器编译(GPU编程)
- REPL环境
完整的编译流程总结:
1 | 源代码(.c) |
或者使用完整的编译命令:
1 | clang -O2 Test.c -o test # 一步到位:源码 → 可执行文件 |
clang会在内部完成上述所有步骤,使用管道(pipeline)在内存中传递中间结果,避免生成中间文件。
额外的有用工具:
1 | # 查看LLVM IR的控制流图 |
相关链接:
[1] LLVM和Clang背后的故事
[2] 关于LLVM,这些东西你必须要知道
[3] The Architecture of Open Source Applications: LLVM
[4] LLVM’s Analysis and Transform Passes
[5] LLVM Language Reference Manual
[6] Getting Started with LLVM Core Libraries
[7] LLVM Cookbook